
There is a lot going on in analytics right now – much of it catalyzed by browser privacy changes. These changes can be scary! We’re now in a world that’s considering server-side tracking. As a front-end guy, that’s super intimidating. I have about 10 blog posts that are half-written. One talks about the state of the industry and what I think about the future of server-side tagging. There is one question I couldn’t answer: what happens to data layers? I’m a HUGE advocate of these things. Are they going away? Let’s start by answering some basic questions.
Table of Contents
Will server-side tag management kill data layers?
No.
I mean, it’s technically possible to not use a data layer with server-side tag management. Some gigantic companies already do this in some capacity. It’s also technically possible to get hired as an analyst and spend 100% of your time analyzing. This isn’t the case 99.99% of the time.
Will server-side tag management change data layers?
Eventually, maybe? Probably not.
The bulk of this article will be dedicated to talking about this question/answer.
Data layers in a server-side world
Things are constantly changing. That’s not new. It’s tempting to try to stay on the cutting edge of literally everything, but we don’t really know what the end state will look like. During a conversation on Measure Slack, I asked what a server-side future could look like.
Simo Ahava laid out the primary tagging scenarios, which looks something like this:
- client-to-vendor (direct client-side)
- client-to-server-to-vendor (enrichment via server-side)
- server-to-vendor (direct server-side)
- server-to-server-to-vendor (enrichment via server-side)
We’re going to talk through the first 2, as #3 and 4 are less common.
Client-to-Vendor
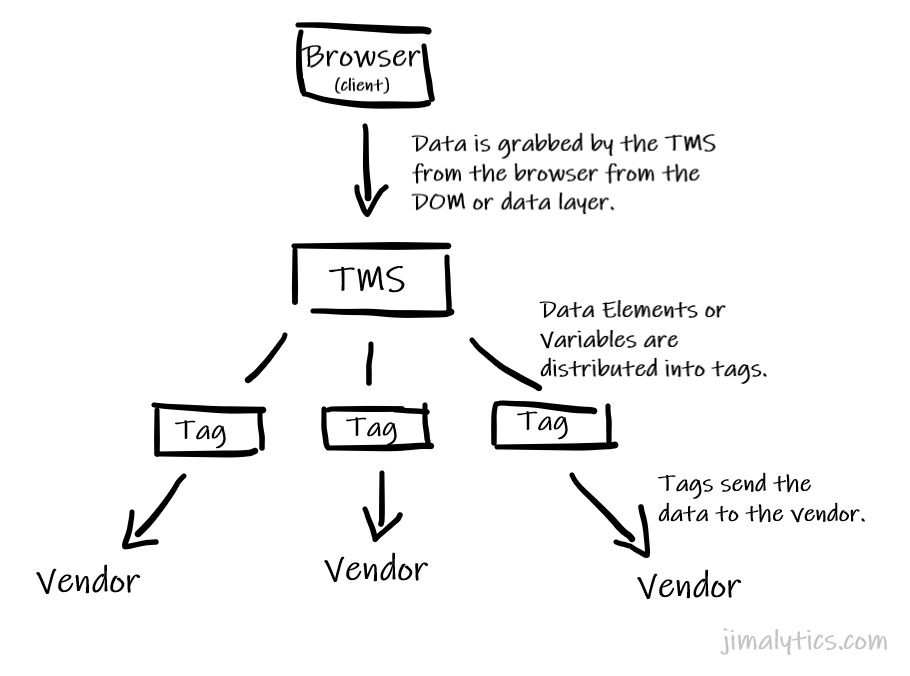
This is what almost all of us do today. Everything happens on the front-end. I’ll get data from my data layer (or scrape it from the DOM), drop them into a tag template (basically JavaScript), and then they’re directly sent off to the respective vendors. Ever set up a Facebook tag in a standard GTM container? Ever configured an Adobe Analytics tag in Launch? That’s what this is.
For most cases today, this is all you need. As it stands, you already know you need a data layer for this type of implementation.
Client-to-Server-to-Vendor
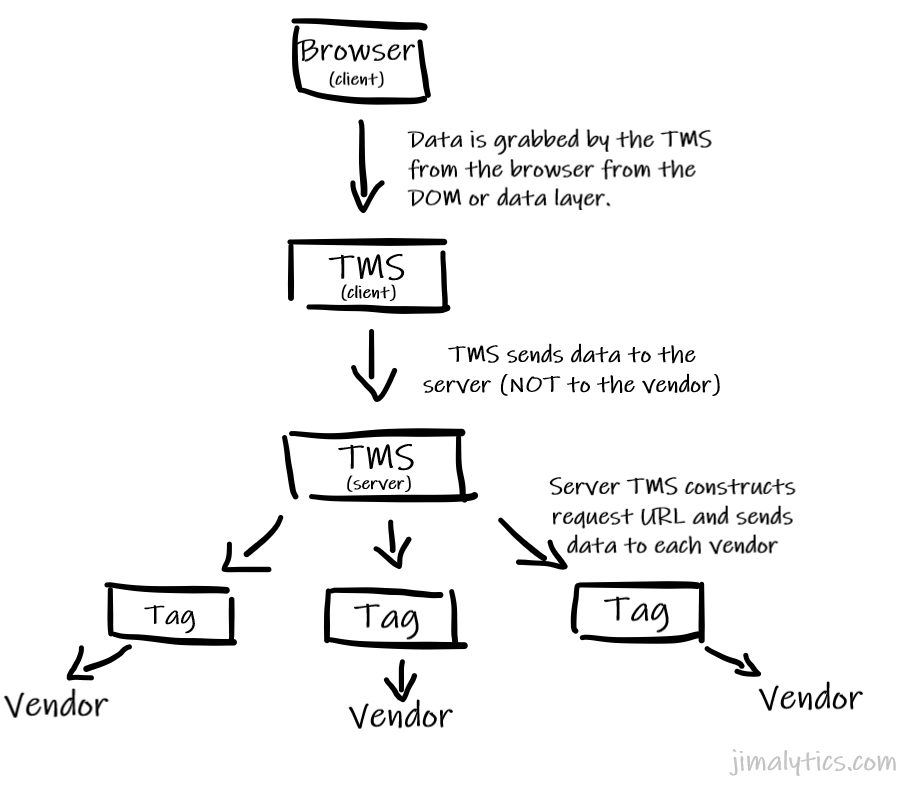
Over the next decade, client-to-server-to-vendor (CSV) will be the most common transition you’ll see… especially now that the vast majority of folks have already migrated to tag management. Does that mean you will have to rip out your data layer? Hell no. In fact, it’s probably going to be the easiest way for you to conduct basic QA.
For a more visual representation, here’s what I’m talking about:
CSV has been around for a while. Tealium has had that baked into their TMS since the dawn of time, but Google’s beta of GTM server is quickly accelerating it into the mainstream. That said, adoption of server-side tag management will not reach the same adoption rate as regular client-side tag management just because of the extra technical/cost overhead. You can’t just install it with a plugin in WordPress.
That said, media vendors may eventually require a server-side implementation in order to provide support. If that happens, the flood gates will open.
Where this is all going
No matter how you slice it, server-side tag management doesn’t impact the need for a data layer. I wrote and deleted an entire section talking about how data layers may become smaller… how we may start using data import features more frequently. I also wrote about how communication between IT and Analytics will become more critical than ever. With both of our teams better understanding each others’ needs, it could bridge an education gap of client-side analysts not understanding what can be grabbed from the server. There was an entire convincing argument there… and then I remembered media vendors.
As long as media vendor technology is inconsistent and the data completely decentralized, we won’t move away from large page-level data layers.
Final Thoughts
To answer the question the title poses – you’ll still need a data layer. As long as people are interacting with a browser or screen of some sort, there will be a need for a client-side component. Sometime in the next decade, most companies that can afford an analytics/media team will be using some kind of Client-to-Server-to-Vendor methodology. Server-side tag management isn’t something that you just plop onto the site. It’s not a snippet of JavaScript. You’re configuring a server.
I think we’ll hit some kind of inflection point with all of the changes with cookies and privacy. Vendors will say the only reliable data will be from server-side tag management. This inflection point will be superficial. We work in an industry of accuracy, not precision. We should have gotten comfortable with incomplete data over a decade ago; but I find myself continually explaining to people that analytics (regardless of platform) is a website behavior contextualization tool.
Moving to server-side isn’t a bad thing. In many cases, it’s a good thing. However, if you’re doing it because your numbers don’t match up within 3% of your transaction database then you’re doing it for the wrong reasons. The more intriguing, lingering thought I want to leave you with is this: the digital analytics industry seldom drives digital analytics innovation. The media industry drives analytics innovation (yes, I know there’s overlap). If you want to know where things are going (not necessarily where they should go), follow ad tech developments.
Shout-out to Cory Underwood, Simo Ahava, Lluis Villarejo, Stew Schilling, and others for answering many of my dumb questions. Speculation in this article is my opinion and does not necessarily reflect that of those mentioned.
**Analytics is an industry of precision, not accuracy.
The data will never be perfect (accurate), but should be consistent (precise).
Hi Dr. Gordon, this is a great and simple article I wanted to write a long time ago, thanks for taking this off of my to-do list and even providing us with some easy-to-understand sketches… :)
So when you say “server side” tag management – are you referring to the Client-Server-Vendor model? I’m guessing yes.
I ask this because wIth all of the talk around this topic, I see Server-to-Server, Server-Side, and Server-Side-Forwarding are often used interchangably, but can mean very different things to people. Your Client-Server-Vendor is a Server-Side-Forwarding flow, as I understand the term. I often hear people say “server to server” when talking about that flow, but Server-to-Server usually means sending data directly from the sites servers to another server which completely bypasses the client.
If I was to say “Server Side Tag Managment” to my IT team, they would assume I want them to have our servers sending calls directly to other servers like Adobe. I’m usually not a stickler for terminology, but many technical people are, so it gets confusing for them.
do we need to Implement the Data Layer Separately for Server side or can we pass the Data Layer Values From Client side to Server side.
Some tags change the DOM (add a link, show a popup etc) . How can these work with server side tag management? I don’t think they can, they have to be on the page.
Hey Jim – Yep, those tags would likely need to be deployed via client-side TMS.