
A dataset is where data lives. With any of my guides, the first thing I want to do is link to Adobe’s documentation on datasets. It’s pretty good. The intro paragraph does a great job at explaining what the heck it is (in contrast to datastreams). There’s this data lake. A dataset is the water in the lake. I mean, it might not be all of it. Like if you have 2 datasets then 1 dataset will be some of the water and the other dataset would be the rest of it. You get the idea, though, right? A dataset is your data.
A lot happens before data lands in a dataset, which has me thinking… we have data streams and we have data lakes. What’s a schema? Is that like… a water treatment plant? Is untreated data just sewage? Also, I feel like data sources aren’t getting in on the action. Are those springs? Data… glaciers? At what point did we decide that data streams, lakes, and lake houses were super sexy but then we’ll just slap everything else with some literal technical term? Someone has to look out for the rest of the crew.
I digress.
Table of Contents
What does it do?
The dataset holds your data. Any data. Profile data, product data, website data – anything. When you click Create Dataset, you’re greeted by 2 options. 99.99% of the time, you’ll select “Create dataset from schema”:
That means you have to already have a schema to create your dataset. Not sure how to do that? Check out the guide. If the data you’re ingesting matches the schema, it will come back as a successful batch. Otherwise, it will return as a failed batch, meaning those records were not ingested into the dataset. More on that later in the article.
Okay, so what’s this other “Create dataset from CSV file” thing? Well, you can upload ANY data via the CSV file upload. So… that sounds really nice, but what does it do? Honestly? I have no idea. I can’t modify the schema. It sure would be nice if I could upload a CSV and auto-generate a schema (hint hint, Adobe)… but you can’t modify the schema. It’s an “adhoc schema” – which is a static auto-generated schema. You can’t copy the schema JSON (which would be nice). You can’t duplicate it into a schema that you can modify. I’ve spent way too much time talking about a feature you won’t use until Adobe figures out what to do with it. Maybe it’s for data hoarders, but I haven’t yet gotten a clear answer (again, hint hint). Anyway, moving on.
What does the profile button do?
Okay, this part is important. Toggle this thing if you want your data to work with RTCDP. Here’s Adobe’s documentation on it (it gets the job done). As an AEP enthusiast like myself, you’re now wondering: what’s the difference between this Profile button and the Profile button in schemas? GOOD QUESTION!
The toggles are a different color. The left margin of the tooltip icon is also a little off. Okay, but seriously. The difference is this – the Profile button on the Schema locks it down (as-in, you can’t delete fields). It needs to be locked down because as soon as you set the Dataset to profile, AEP starts working its magic of merging records. If you’re out here removing stuff, let’s just say server costs would go wayyyy up. Interestingly, the tooltip for the schema says:
When a schema is enabled for Profile, any datasets created from this schema participate in Real-Time Customer Profile, which merges data from disparate sources to construct a complete view of each customer. Once a schema is used to ingest data into Profile, it cannot be disabled. See the documentation for more information.
This does not seem correct because you also have to enable Profile on the dataset. THAT is the button that says “Use this data for RTCDP.” You can have datasets that do not collect Profile-enabled data from Profile-enabled schemas. Might be an edge case, though.
What are all of these Dataset statuses?
When you pipe data into a dataset, some stuff will happen. Here’s a list of that stuff:

Most of you probably won’t see Canceled. Few of you will see Loading. The other ones are pretty common. In fact, you might see the Failed status quite a bit – but it’s no cause for alarm. If a batch “failed” – it doesn’t mean the good data is tossed, too. The interface doesn’t do a great job at showing just how many physical records were discarded. This is from the Dataset Activity window (click on the dataset from the Browse screen):
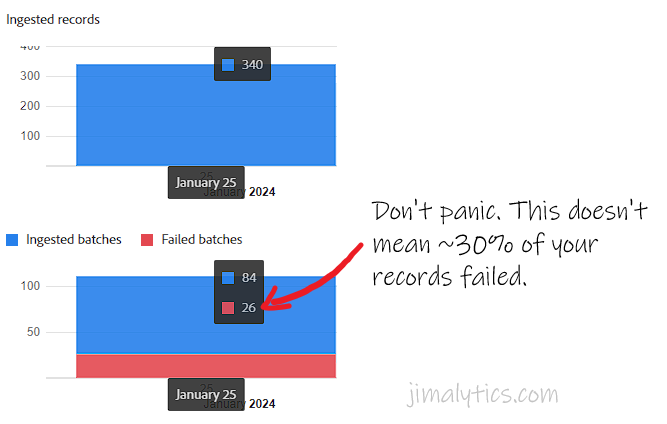
The chart is accurate, but misleading. 26 batches failed and 84 succeeded… and 340 records were ingested. Huh. Unfortunately, Adobe doesn’t include “Failed records” in that chart. If they did, you’d see that it would only be about 26 total failed records. The failed batches of data live in a separate batch (it’s like a batch inside a batch). Moral of the story is if you see a lot of red in the chart, don’t panic. Address it… but don’t panic. The fix might be as simple as enabling partial batch ingestion. I don’t know what a “best practice” is for partial batch ingestion (basically lets you upload data even if it has errors on X% of the data).
I like to live dangerously so I’ll crank it up to about 10%. That means that my data won’t get thrown out if I trigger errors in under 10% of my server calls. Yay.
One big problem is it’s tough to run diagnostics on failed batches. Well GOOD NEWS! At Adobe Summit 2024 my colleagues and I at Blue Acorn iCi will be showcasing a tool that solves for this. And it will be a Chrome extension. And you won’t have to leave AEP to use it. Also it’s free. Stop by our booth and check it out. Seriously, it kicks ass.
Should I use 1 dataset for all of my websites or separate ones?
There’s no perfect answer to this. You should use a common XDM architecture (read as: use the same basic schema). If you have 1,000 websites, I’d use 1 schema. If you have 3 and each site has weird stuff you want to add to the base schema then I might be tempted to use 3 schemas with the same base architecture and 3 datasets. You’d just combine them in your Connection settings in CJA. Everything is tied together via the identity map anyway (assuming you’re carrying over an ID between sites).
Final Thoughts
There’s more to datasets. There’s meta tags, there’s uploading JSON, and this “Error Diagnostics” toggle that exists for some reason (why is this an option?). You can add datasets to a FOLDER! How do you access the folder? No idea. When inspecting a dataset, there’s Data Governance tab is just an echo of the Schema tab. I never quite appreciated having features live in 1 place instead of 12 like I do when I navigate through AEP. Sometimes less is more. And with that, there’s not much else to say about datasets.
Up next I plan to walk through Profiles and Identities!