
So… should you use a data layer?
Short answer: Yes.
Long answer: Yes. I’ll explain why.
This is a simple concept, but I’ve worked with enough experienced analysts who still do not buy into this best practice. I’ve heard every excuse of why someone won’t implement a data layer and as I get older it’s getting more difficult to unroll my eyes. Excuses… all of them!
What even IS a data layer?

Okay, this might be the one good reason you don’t use a data layer. You don’t know what one is. That’s okay, here’s a good place to start. I’m trivializing some stuff here, but a data layer is a fancy word for a hard-coded JavaScript variable.
For instance, let’s say we want a data layer for a blog or a news article:
var dataLayer = {
authorName:"Jim Gordon",
publishDate:"1/1/19",
articleCategory:"Data Implementation"
}
I can now dynamically grab the author name, publish date, and article category and use it with my tag management system to send this information to my analytics tool. You can physically see this code in the page’s source code, meaning a developer has to implement it.
We don’t have the developer resources for it, though.

How the hell did you get anything done before tag management systems? You know… a few years ago when every event had to be implemented individually by developers. We didn’t stop implementing inline just because we found a shortcut. It changed shape and the industry just hasn’t felt like there was an incentive to adapt.
Maybe you were just measuring pageviews – and now you’re able to get more data without having to scratch and claw for developers’ time. Odds are you’re taking this new data and adding more recommendations to that backlog that’s clogged with urgent “fires” and competing priorities. You have other problems to solve right now (READ: HIRE MORE DEVELOPERS) – and getting more data inefficiently will change your job title to “Implementation & Reporting Micromanager”.
Getting this data could help justify more development resources.

I look forward to reading your case study on how collecting more data via CSS Selectors and JavaScript has helped your IT team justify hiring more developers. Seriously. I will rewrite this entire article if you have one and can talk to me about how you did this.
I’m not talking about people who just transitioned TO a data layer. I’m talking about those who didn’t have resources to implement a data layer – and then collecting more data with your CSS selectors inspired leadership to hire a developer to implement a data layer.
Like… they didn’t just say “why would we hire someone if you’re already collecting the data just fine without it” and instead consciously understood that a data layer would eliminate long-term maintenance and data quality issues.
“Why would we buy you a car when you can walk for free?”
But I can get the same stuff much faster without a data layer.

Now we all know it’s super easy to implement and check that box off of your list. Wait a second…
If the page is translated by Google Translate, it will grab whatever that language is. In case you didn’t know, there are a LOT of languages out there. But most people speak English so you won’t get a TON of junk data.
If the page even changes, your tag could break… but your site never changes, right? I’m sure you also have an air-tight process where the dev team communicates every class name and ID that’s being added or removed. It’ll probably only get easier as dev cycles get more and more aggressive.
I’m sure you won’t need a bunch of JavaScript to support this, either. Everything is probably super-accessible.
Let’s face it – there is NOTHING about this that is sustainable. When you skip a data layer, you’re choosing fast food over a healthy meal. It’s fast, it’s easy – you don’t have to think about it. Months go by and now your blood pressure is through the roof and your full-time job is micromanaging tags and filters while also trying to build a process for developers/designers to actually communicate what exact changes are being released… and then have to sift through all of the noise of the stuff that won’t affect your implementation. Odds are you don’t have communicable documentation of your tagging specs. You’re choosing short-term convenience over long-term sustainability.
Does this mean that the data layer is immune to site changes? No, but the likelihood of a developer accidentally removing it is VERY low; and if it happens… you’re not accountable. You’ll actually have reference documentation to back it up. When you forego a data layer – documentation is another silent victim.
We HAD the development resources, but now we’re up against deadlines!

This is a time management and process issue.
Let me say this again – this is a time management and process issue.
Filling in the gaps for development teams is unsustainable and there are various ways to solve for it. The best way to solve for teams not prioritizing data layers is to set the precedent that an analytics implementation requires one. Do not give them any other option. Options make it optional – and the easiest option will be exercised. Tell them data layers are necessary and DO NOT tell them that you can do you work without it.
You should use a data layer.
Rereading this post, it sounds like I’m blaming developers for not implementing a data layer. I’m not. I’m also not necessarily blaming the analyst. We have very limited control over stuff like resourcing and prioritization. The inability to implement an effective data layer is a symptom of a larger problem.
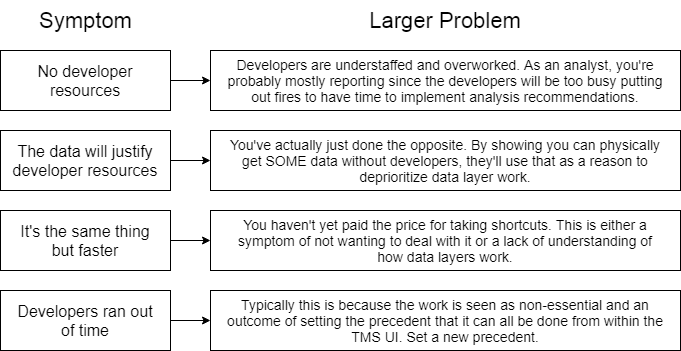
As an analyst, I might have an existential crisis if we don’t have the development resources to implement a data layer. Do they even have time to implement your analysis recommendations? If not, what’s your purpose? Are you there to just collect data and churn out reports? Building out an analytics team requires a level of scale that your organization must accommodate with a supporting cast of developers.
I’m aware that some people can physically get away with using CSS Selectors and JavaScript… especially if you’re a vendor. Why not? You need to meet a deadline – getting it done without developer support makes a really nice sales pitch! Don’t forget those sweet hours you’ll clock in from that maintenance retainer. As more companies adopt Agile (or bits and pieces of it), releases become more frequent. Each release is an opportunity for your tags to break.
For the rest of us who want to do right by our clients, our stakeholders, and ourselves – let’s use a data layer. What this post DOESN’T address is how to build sustainable processes and documentation. You CAN get to a point where you trust your developers to implement a data layer with new releases, minimizing documentation and QA. How do I know? I’ve done it… and worked alongside folks who have done the same.
Yup
Yup. #true
Great post, Jim! I love it!
I’ve been working on solutions topic over the past couple of years and have come to clarity on a number of the questions that you pose.
1) Not so much, “What is a Data Layer?” But specifically what form should it take. We started with the requirement that we needed a solution that would handle not only traditional static HTML sites but also the highly interactive sites produced with Angular, React, Vue, etc. We also needed to handle the new Async embed option for Launch and asynchronicity in general. We ended up with an event-based data layer formed on top of a native JS Array. We ended up with something that looks a bit like the GTM data layer but also has aspects of the W3C CEDDL from 2013.
2) What is a Data Layer Manager? In order to make the implementation as clean as possible, we decided that we would provide a single pattern for application developers to follow when communicating to the TMS (or any other consumer). That pattern is as simple as myDataLayer.push({“event”:”My Event”, “eventData”:{…}}); But making the “API” as simple as possible, we had to take the responsibility for processing, and event dispatch (triggering rules in the TMS) ourselves. The Data Layer Manager is the component that we built to do this. We’ve provided this for users of Adobe Launch as the Data Layer Manager extension which is freely available for use. We also use this code base for new GTM implementations as it allows extra functionality not provided by GTM.
3) How do I validate Data Layer Events? This is a big governance headache and it hurts the head and heart of most humans to do it manually. An extended feature of our Data Layer Manager is the ability to provide a JSON schema for each event. This schema is used for validation of every event that is pushed to the data layer by the application. Using JSON schema allows us to define which properties are required, what data types are expected, what formats are acceptable and so on. This validation provides immediate feedback to the application developer who is charged with the implementation of a data layer event. It also provides automated validation in QA and soon will provide on-demand sampling and aggregated validation in production environments.
4) How do we retain the agility of DOM scraping whilst retaining the best practice of using a Data Layer? My take on that is is that we DEMAND THE DATA LAYER and we build out TMS rules and tracking based on its existence. We use the speed and agility of DOM scraping to provide the data layer pushes as temporary shims until the application developers provide the formal solution. At this point, we knock out the shims, validate in QA/Staging and seamlessly transition to the application provided data layer event. By adding a “shimmed” attribute set as a boolean to true/false, we can maintain tracking of those events still running on provisional pushed data layer events.
Thanks, Stew! Love it. I agree 100% and am looking forward to reviewing the Data Layer Manager.
Hey,
non-developer here. how can i actually code the dataLayer.push, im looking to learn. (:
Thank you in advance,
Pablo