
This is my follow-up to my last post about AEP Schemas. In this post, we go into specific fields in a schema. We’re going to go into gory detail. I want to direct you to Adobe’s own documentation on this, too. It’s pretty good but doesn’t quite go as deep or hypothetical as I’d like – so here we are! We’re going to structure this in “what happens when…?” format because that’s how I look at some of these options. If I do [a thing] then what actually happens? Why wouldn’t I just push the “Identity” button on every single field? That’s enough of an opener. Let’s dive into it.
Table of Contents
What happens when I set a field name?
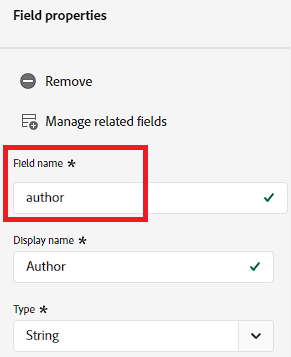
If you think about data like a key:value pair, the field name is the key. When you reference that data point (or array) like a variable, this is the name you use. The field name will have no spaces or special characters – just like any JavaScript variable. When you name your field, it’s important to name it something unique.
Okay, that’s all well and good – but what does that even mean? Well, as it turns out, uniqueness is only meaningful in terms of the object path. That basically means that I can have these 2 fields:
Schema 1 > orgObject.firstName
Schema 1 > orgObject.person.firstName
However, I CANNOT do the following without reusing the same exact firstName field:
Schema 1 > orgObject.firstName
Schema 2 > orgObject.firstName
What I mean here is you’ll need to add the field group where orgObject.firstName exists. This is to prevent a conflict in rule definitions. If one field says it can have a max length of 10 and another has a max length of 15 then we’re gonna have a bad time. But who cares when you can only have 1 schema for 1 dataset? Well, the downstream tools like CJA use those object names as common keys. Even if we’re using 2 completely separate datasets, if we have path overlapping it’s going to cause problems.
When you create field names, it’s important to consider that you may want some fields nested in some object that adds context. Like form.firstName vs. purchase.firstName. We’re assuming we don’t want one to overwrite the other in this case. In all other cases, it makes sense to just use the same field across schemas.
What happens when I set a display name?
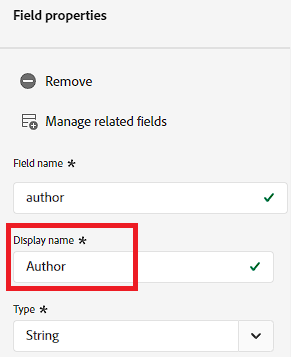
Display name is what it sounds like. Your field names should be pretty as close to natural language as you can get it, but sometimes you have something like ipAddressMD5Hash which is a name only a sadist would show a marketer. Instead I might name it “Anonymous IP Address”. That’s the display name. This name doesn’t have to be unique, either! I just went in and named all of my fields “Hello World” and now every single one shows up as “Hello World” when I toggle “Show display names for fields”:
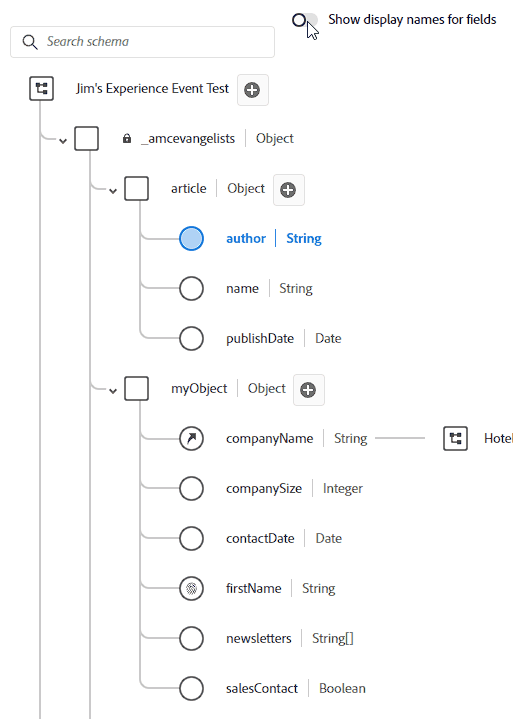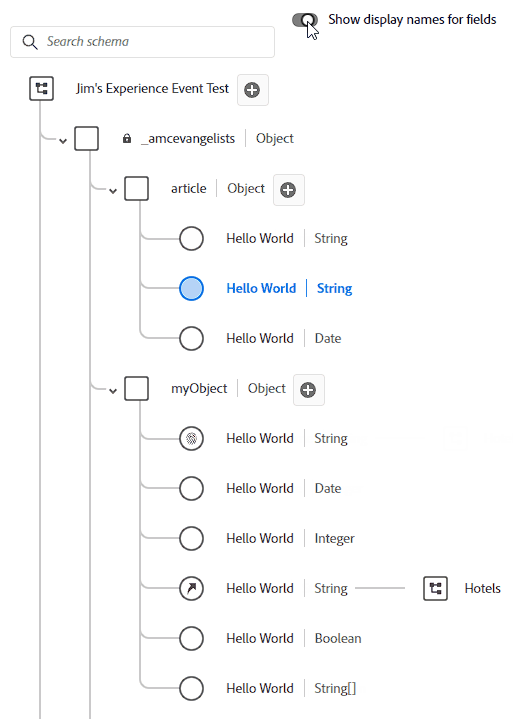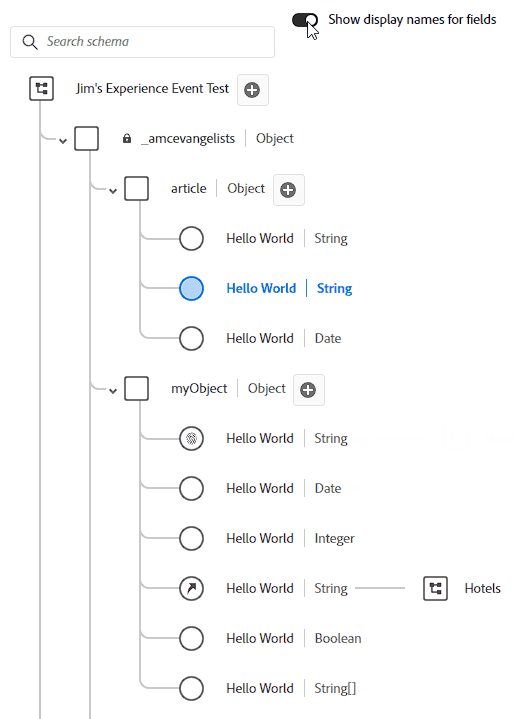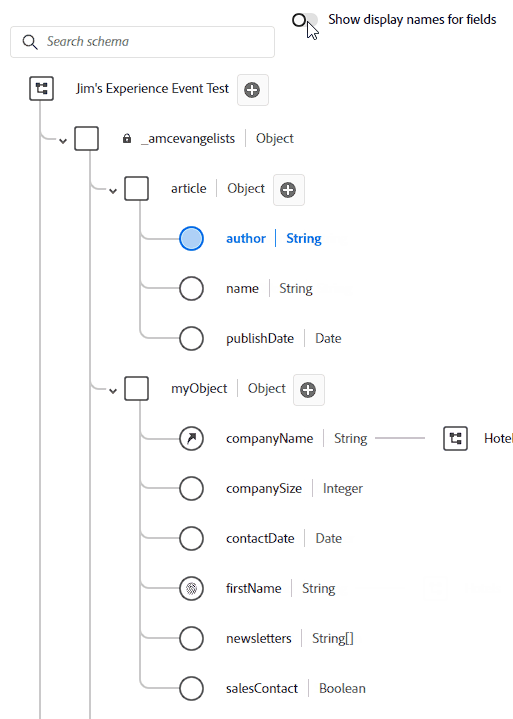
So what happens when you do this? I mean, if you look back at the field name section we might have multiple First Name fields. I guarantee you’ll eventually have something overlap at some point. Whether it’s Product Name, Category, Type, or some other field that’s reused a million times in a million tables – in CJA it names it like a file naming system. Let’s say we have 3 instances of Product Name – CJA will show:
Product Name
Product Name (1)
Product Name (2)
You’ll want to check the path to see what schema or table it corresponds to. You can change its name in CJA or in the schema. I do recommend using this as a bit of a flag that you need to clean your stuff up.
What happens when I define a type?
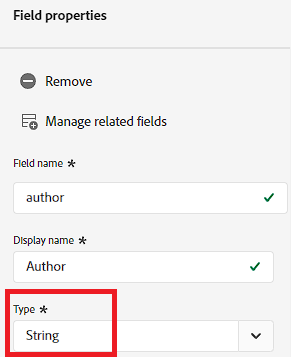
Next to field name, this part is the most important part of creating a field. What type of value should AEP expect? I don’t think I need to spend a whole lot of time talking about what each one is because there are way better articles talking about what a “string” vs. “integer” vs. “boolean” etc (literally the first result when searching for “data types”). While that’s been covered ad nauseum, there’s an interesting little wrinkle here. You might see more than just those default data types.
There’s a reason I didn’t link to Adobe documentation when I talked about data types. That’s because their documentation dives straight into custom data types. That’s the wrinkle. I wrote about them in my Schemas guide. You can create a Data Type that’s actually a group of fields. So when you select a Data Type like “Account Details” in your dropdown, it’s basically a field group (which I recommend using instead of creating custom data types).
What happens when I assign to a Field Group or Class?
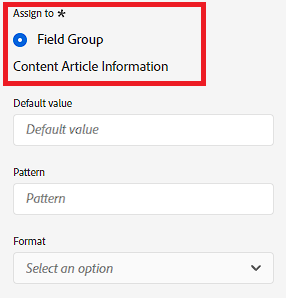
When you create a field, it has to be assigned to a field group or class. We talk about field groups vs. classes in my Schemas guide. I’m just going to talk about what happens if you assign it to a Field Group… because PER MY LAST EMAIL ARTICLE I said it makes sense to keep design patterns consistent so let’s just stick with using field groups. They’re versatile enough.
Before creating your field, you should already have a good idea as to whether this is something that’s unique to this schema or something that might be reused in conjunction with other fields. Let’s say you’re creating a set of fields for a contact form – I would have a field group for Contact Forms. So… if you’re creating a new field that you want to add to the group of fields you made for contact forms – add it to that field group. If this is ad-hoc, you might have a Field Group that’s specific to the schema (though that’s not super strategic). If you literally have no idea if it will ever be used again, you can just type gibberish and it’ll create a brand new field group with that name (don’t do this).
Instead, you’ll want to be strategic in how you name and organize your field groups. Don’t just create 1 field group for 1 schema. That’s… lazy. Instead, group stuff up like Page Properties, Website Properties, etc. That will give you flexibility to add fields and propagate them in a global architecture. The more you include in a field group, the more ad-hoc your additions will get, so be careful and intentional. For instance, not every website you have will have a newsletter – so don’t include it in a Global Website field group. Know what I mean?
What happens when I set a default value?
Setting a default value will do exactly as it sounds (just like a Data Element in Launch) – if a value isn’t there then it’ll fall back to some other value that you specify. So let’s say you’re collecting input from a form and someone didn’t fill out all of the fields (and that’s okay!). You might want to fall back to “Empty”. This can be important because it will let business users more easily understand that you ARE collecting data from this field and they won’t have to come to you asking why you got 100 responses for First Name and 99 responses for Last Name.
So what happens if I set a default value AND I set it as a required field? If you’ve marked a field as required then setting a default value does nothing. The order of operations is first check if the field is required – if it is and the value isn’t there? Throw it out. If it isn’t required then fall back to the default value (if one is set).
What happens when I define a pattern?
This is regex. Instead of calling this “Regex Pattern” it’s called “Pattern”. It should be renamed to “Regex Pattern”. I’m dunking on this field because it’s named like a developer would name a field “Well, duh – it’s a schema so it expects a regex pattern. Seems redundant.” However, while these assumptions were being made, we also have to make the assumption that it shouldn’t include the slashes before and after a /RegEx pattern/.
This is a RegEx pattern and whatever data is processed has to match that pattern (including individual strings in an array) otherwise it fails and is tossed. It doesn’t have to be a complete match, either. Also, you just need to input the pattern and not the slashes.
What happens when I define a format?
You probably won’t be using this field in conjunction with pattern because this specifies a really really specific format in which AEP expects the data. Adobe’s documentation does a good job at covering this one with links to how it spot-checks values passed into a field with this format. I’m going to guess that 99.9% of people who set a format will use Email or the Date-Time.
What happens when I define a length?
This one is pretty straightforward. You can set a minimum and/or maximum length of a value (in character count for strings). If you go below the specified length or above it, the record will be tossed.
What happens when I define a min/max value or an exclusive min/max value?

For Doubles, you can set a minimum or maximum numeric value (for instance, maybe it has to be somewhere between -14 and 12). You can also set EXCLUSIVE min/max values. Here’s the difference:
Min = 0, Max = 1
x >= 0
x <= 1
Exclusive Min = 0, Exclusive Max = 1
x > 0
x < 1
This is important because you don’t want to have to manually set a max value of something like 0.99999999999. Makes way more sense to just change the operator.
Keep in mind – AEP schemas will let you save a schema where the Max < Min. So make sure you don’t accidentally set a max value of 0 and a min value of 1. Your data will get tossed.
What happens when I set a description?
We’ve entered the part of this post where stuff isn’t covered by Adobe documentation! Yay, incrementality! So what actually happens when you provide a description? Can other people see it? If so, where? What is the difference between a description and a note?
Well, it’s all in how it’s shared in the other interfaces. Descriptions are public. That means that they appear in places like CJA when you look at the information of a dimension. I recommend always including some bit of context here because we want people to understand what the hell the value actually means. So let’s say you do NOT provide a Display Name for pageview and someone has to find it in CJA – when they finally find this web.webPageDetails.pageViews.value thing they will know that this actually means it is a pageview and not some weird codey thing that’s clearly not important enough to name (please add display names).
What happens when I add a note?
Unlike a description, a note is only viewable in the Schema interface and often includes stuff that analytics nerds will care about – like update history and nuance that would not make sense to anyone except someone who is messing around with a field. When you SAVE a note, it saves the text in the box and does NOT include timestamps of the note that’s being added. You will have to add that in manually. This is unlike some of Adobe’s other tools that will actually save notes like a comment thread with a name associated with it.
I think this functionality can be somehow improved. Honestly, I could (but won’t) argue that this could be removed in favor of some kind of schema publishing workflow that outlines stuff that was changed. If you invest an hour into a field, I’d spend 59 minutes on the description and 1 on the note.
What happens when I require the field?
Requiring a field means the field has to have a value for the data to be processed. If it does not have a value, it’s tossed. Okay, so there IS quite a bit of nuance to this. I had to choose my words carefully on those first 2 sentences. If the field does not have a value, it is tossed. We’re making a few assumptions here. The first is that the field exists in the payload. If the field does not even exist in the payload (under the circumstances I tested) then the batch will be processed. However, if you attempt to populate the field and the value that’s returned is undefined, null, or whatever – then it will fail.
In addition, requiring a field and having a default value makes no sense in the first place – but let’s say you do have a default value and you require a field. AEP will check for the field requirement first – so if you set a default value and the field comes through as undefined, the record ingestion will fail.
What happens when I set it as an array?
For strings, you can set a field to be processed as an array. This is an AWESOME feature for when you want to pass in multiple items that correspond with an event. So let’s say you have something like a site search where you have multiple filters applied to a search – star rating, price, etc. I want to pass in an array of search facets that are being used so I know what people actually care about when they look for something on the site. I would set the String as an array and pass the objects as an array. My Data Element might look something like this:
["product rating", "price", "availability"]
In theory, I could look at an individual search and add the Facets as a secondary dimension and see all 3 of these as the facets that were used for that 1 search. Super easy (think listVars or listprops).
What happens when I select “Enum & Suggested values“?
When I read this option, it literally means nothing to me – so let’s break it down a bit. Enum is… a made-up thing. Suggested values means value are… suggested… to AEP? Or something? It makes so little sense, there’s a tooltip that uses a paragraph to explain it. They’re so confident it could make sense, there’s literally an entire support page dedicated to it. Okay, let’s see if I can do it with less than that in human terms:
Suggested Values: Prepopulates a dropdown in AEP tools (like segmentation) for marketers of stuff that matters. You can ingest other stuff.
Enum: Prepopulates a dropdown in AEP tools (like segmentation) for marketers of stuff that matters. You can’t ingest other stuff. Like it’ll reject the data.

I really love this feature, but think it could be communicated and implemented WAY better. Definitely watch that video in the support page I linked above. I DO have some lingering questions – like… is it case-sensitive? I’d assume so.
What happens when I set it as an Identity vs. a Relationship?
Let’s start with the simple bit of this. Identity. What is an identity? Marking the field as an identity means you’re saying it represents a unique identifier for a person. That could be an email address, user ID, full name, or whatever. It should be unique. If it’s set as a primary identifier then it will be assumed as the primary key. So it’ll tie this data together with any other identity in any other table using an identity in the same namespace (namespace is something like ECID). So any other table using the same primary ID will stitch together and be usable associated in RTCDP and RealTime customer profile.
A relationship is different from an identity. A relationship might be a transaction ID that you want to associate with another table that has transaction IDs. A transaction ID isn’t an identity. Jim Gordon !== Transaction 012451262. However, we still want to associate that with another table. Now in CJA you can establish this via a Lookup… but that’s only going to get you where you want to go in CJA. If you want to establish a relationship with the rest of AEPs tools, you will want to establish a relationship. That way RTCDP knows that when you’re looking for people who bought socks, it’s also associated with that session where they first browsed shoes. So in RTCDP I can then say – of the people who bought socks (I know this because I got the information from my purchase database), send an email to them with the shoes they were looking at (information from my website data, tied together via transaction ID).
So I had to change the way I thought about Relationships and Identity for this. When we talk about relationships and identities, my brain instantly goes to “Okay so how is this going to look in CJA?” Why do I think that? Well, it’s just how I’ve been programmed for the past 20 years. When you think about identities and relationships (mostly relationships), you have to think outside of just how it’s going to look in a data view and instead think in the context of… well… everything else. By setting identities and relationships you’re telling every application in AEP that a connection exists. That’s just so when you’re building audiences in RTCDP you don’t have to constantly state and restate relationships. You define it once in the schema and the rest just works.
Final Thoughts
Whew. This isn’t my longest article, but testing all of these permutations is exhausting. Building a schema isn’t easy. AEP is also a work in progress, as it uses a lot of terminology that analysts aren’t accustomed to. While it would be nice to change some of it (like “enum” to “dropdown”), it’s also difficult because there are a lot of different types of users who are in the platform. For now, it’s a little easier to just adapt and learn. I hope this helped with answering some questions about some specific use cases. Adobe’s documentation does a great job, but isn’t designed to go into specific usage. My next guide will be on Datasets. Keep an eye out in the coming weeks.
1 thought on “Adobe AEP Guide: Schema Fields”